Wildcards and Regular Expressions

Contents
Wildcards let you specify a file or group of files by typing a partial filename. The appropriate directory is scanned to find all of the files that match the partial name. You can also specify files with regular expressions.
Wildcards are usually used to specify which files should be processed by a command. If you need to specify which files should not be processed, see File Exclusion Ranges (for internal commands), or EXCEPT (for external commands).
Most internal commands accept filenames with wildcards anywhere that a full filename can be used. There are two wildcard characters, the asterisk * and the question mark ?. Additionally, you can specify a set of characters. Note the issues about matching short file names.
WARNING: When you use a wildcard search for files to process in a command like FOR or DO, and you create new filenames (whether by renaming existing files or by creating new files), the new filenames may match your selection wildcard, and cause you to process them again.
TCC also supports wildcards in the directory names (but not in the drive name). You can control the subdirectory recursion by specifying * or ** in the path. A * will match a single subdirectory level; a ** will match any all subdirectory levels for that pathname. Directory wildcards also support regular expressions. Directory wildcards cannot be used with the /O:... option (which sorts entries before executing the command). And think very carefully before using directory wildcards with a /S (recurse subdirectories) option, as this will almost certainly return unexpected results! There are a few commands which do not support directory wildcards, as they would be meaningless or destructive (for example, TREE, @FILEOPEN, @FILEDATE, etc.).
For example:
| del c:\test\test2\*\foobar | Delete the file foobar in any subdirectory of c:\test\test2 (but not in any of their subdirectories). |
| del c:\test\**\*foo*\foobar | Delete the file foobar in any subdirectory under c:\test (and all of their subdirectories) that has "foo" anywhere in the name. |
| del c:\test\t*2\foobar | Delete the file foobar in any subdirectory of c:\test that begins with a t and ends with a 2. |
An asterisk * in a file specification means "a set of any characters or no character in this position". For example, this command will display a list of all files (including directories, but excluding those files and directories with at least one of the attributes hidden and system) in the current directory:
dir *
If you want to see all of the files with a .TXT extension:
dir *.txt
If you know that the file you are looking for has a base name that begins with ST and an extension that begins with .D, you can find it this way. Filenames such as STATE.DAT, STEVEN.DOC, and ST.D will all be displayed:
dir st*.d*
TCC also lets you also use the asterisk to match filenames with specific letters somewhere inside the name. The following example will display any file with a .TXT extension that has the letters AM together anywhere inside its base name. It will, for example, display AMPLE.TXT, STAMP.TXT, CLAM.TXT, and AM.TXT, but it will ignore CLAIM.TXT:
dir *am*.txt
A question mark ? matches any single filename character. You can put the question mark anywhere in a filename and use as many question marks as you need. The following example will display files with names like LETTER.DOC, LATTER.DAT, and LITTER.DU:
dir l?tter.d??
The use of an asterisk wildcard before other characters, and of the character ranges discussed below, are enhancements to the standard Microsoft wildcard syntax, and are not likely to work properly with software other than TCC.
"Extra" question marks in your wildcard specification are ignored if the file name is shorter than the wildcard specification. For example, if you have files called LETTER.DOC, LETTER1.DOC, and LETTERA.DOC, this command will display all three names:
dir letter?.doc
The file LETTER.DOC is included in the display because the "extra" question mark at the end of LETTER? is ignored when matching the shorter name LETTER.
In some cases, the ? wildcard may be too general. TCC also allows you to specify the exact set of what characters you want to accept (or exclude) in a particular position in the filename by using square brackets [ ]. Inside the brackets, you can put the individual acceptable characters or ranges of characters. For example, if you wanted to match LETTER0.DOC through LETTER9.DOC, you could use this command:
dir letter[0-9].doc
You could find all files that have a vowel as the second letter in their name this way. This example also demonstrates how to mix the wildcard characters:
dir ?[aeiouy]*
You can exclude a group of characters or a range of characters by using an exclamation mark [!] as the first character inside the brackets. This example displays all filenames that are at least 2 characters long except those which have a vowel as the second letter in their names:
dir ?[!aeiouy]*
The next example, which selects files such as AIP, BIP, and TIP but not NIP, demonstrates how you can use multiple ranges inside the brackets. It will accept a file that begins with an A, B, C, D, T, U, or V:
dir [a-dt-v]ip
You may use a question mark character inside the brackets, but its meaning is slightly different than a normal (unbracketed) question mark wildcard. A normal question mark wildcard matches any character, but will be ignored when matching a name shorter than the wildcard specification, as described above. A question mark inside brackets will match any character, but will not be discarded when matching shorter filenames. For example:
dir letter[?].doc
will display LETTER1.DOC and LETTERA.DOC, but not LETTER.DOC.
You can repeat any of the wildcard characters in any combination you desire within a single file name. For example, the following command lists all files which have an A, B, or C as the third character, followed by zero or more additional characters, followed by a D, E, or F, followed optionally by some additional characters, and with an extension beginning with P or Q. You probably won't need to do anything this complex, but we've included it to show you the flexibility of extended wildcards:
dir ??[abc]*[def]*.[pq]*
You can also use the square bracket wildcard syntax to work around a conflict between long filenames containing semicolons [;], and the use of a semicolon to indicate an include list. For example, if you have a file on an LFN drive named C:\DATA\LETTER1;V2 and you enter this command:
del \data\letter1;v2
you will not get the results you expect. Instead of deleting the named file, TCC will attempt to delete LETTER1 and then V2, because the semicolon indicates an include list. However if you use square brackets around the semicolon it will be interpreted as a filename character, and not as an include list separator. For example, this command would delete the file named above:
del \data\letter1[;]v2
If the Search for SFNs configuration option is set, wildcard searches accept a match on either the LFN or the SFN to match the behavior of CMD. This may cause some files to be found because of SFN match only. In most situations this is not actually desirable, and can be avoided by disabling the option (the default).
Note: The wildcard expansion process will attempt to allow both CMD-style "extension" matching (only one extension, at the end of the word) and the advanced TCC filename matching (allowing things like *.*.abc) when an asterisk is encountered in the destination of a COPY, MOVE or REN/RENAME command.
You can also use regular expressions for file name tests. (The type of regular expressions to use is specified by the Regular Expressions Syntax option.)
The syntax is:
::regex
For example:
dir ::ca[td]
Note that using regular expressions will slow your directory searches -- since Windows doesn't support them, the parser has to convert the filename to *, retrieve all filenames, and then match them to the expression.
If you have any special characters (whitespace, redirection characters, escape characters, etc.) in your regular expression, you will need to enclose it in double quotes. For example:
dir "::^\w{1,8}\.btm$"
For more information on the syntax, see Regular Expression Syntax.
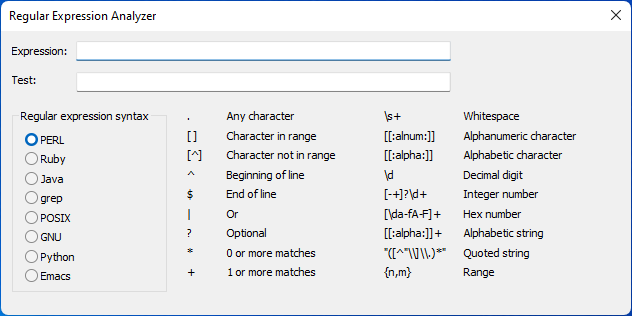
Take Command and TCC include a regular expression analyzer dialog (Ctrl-F7 from the TCC command line, or under the Tools menu in Take Command.) There are two edit boxes:
1) The first is for the regular expression to test.. If the regular expression is valid, the dialog will display a green check to the right of the expression edit box. If the regular expression is invalid, the dialog will display a red X.
2) The second edit box is for the text you want to match against the regular expression. If the text matches the regex, the dialog will display a green check to the right of the test edit box. If the text doesn't match, the dialog will display a red X.
You can choose the regular expression syntax you want to use (Perl, Ruby, Java, etc.). The analyzer will default to the current default for Take Command and TCC.