Okay, I've been looking over the Scintilla documentation and I think I have a better understanding of what's going on. Their docs on
"Character representations" say that
Invalid bytes are shown in a similar way with an 'x' followed by their value in hexadecimal, like "xFE".
That sounds familiar. But... what's an "invalid byte"? In an 8-bit text file, any byte should be a valid character. So... maybe Scintilla is thinking this file uses some other encoding. If it were UTF-8, then yeah; these scattered high-order bytes probably would not form any valid character.
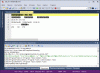
I downloaded the demo text editor, SciTE, and tried opening my silly text file in that:
Looks great. But SciTE has a File / Encoding submenu, which TCEdit
et al. lack. I check, and it's set to "Code Page Property" — which sounds good — but I can change it. And if I set it to UTF-8:
That looks very familiar. So my theory is that TCEdit (IDE, BDEBUGGER) is not correctly recognizing OEM text files; they get misinterpreted as UTF-8.
Which explains another mystery, one that I'd been ignoring. Dmitry, in your first screen shot, somehow there is a Chinese character amongst the hexadecimal. The three Cyrillic letters
ч и к are encoded in CP866 as 0xE7 0xA8 0xAA. Which just happens to form a valid UTF-8 sequence. It works out to U+7A2A, which is 稪. Or, in Japanese,
mojibake.
@Rex: Shall I send you my LooksLikeUTF8() function?